
When the story of the new Covid-19 variant broke, my initial reaction was scepticism. I thought this new strain could just be a random genetic marker that coincided with an outbreak of cases that was caused by behaviour (or even “chance”) rather than by any important biological differences. We have more sophisticated measurement capability for biological data than for social data, and I worry that not enough has been done to rule out social explanations.
For example, despite Covid-19 cases rising dramatically since September mobility indices have remained above the levels they saw in June, which were significantly higher than their April lows. So the UK’s November lockdown only temporarily slowed large scale community spread and did not get it under control.
We already know that people are changing their behaviour. Schools have reopened. We did not need any special biological explanation for why cases have continued increasing.
As we’ll see below, the most rapid increase has occurred in London where the estimated percentage of the population testing positive has likely surpassed 2 per cent. For comparison, most entire states in the US probably have higher rates.
This is not to downplay the importance of taking measures to prevent the spread, but rather to question the necessity for any additional explanations (mutant strain) on top of what we already knew.
Certain decision makers – like NERVTAG, which includes no statisticians – conflated correlation with causation
There is some evidence to suggest my initial theory is wrong – and that these mutations are causally important. South Africa has seen a new strain with a similar mutation recently become the dominant strain while case numbers have increased even though it is currently summer there. But I still think I may be right – and that data recently released in the UK reinforces my theory.
The ONS study: tracking the new Covid variant using PCR tests
The latest background about the detection of this new strain also helps explain this data. From a Science magazine article:-
A fortunate coincidence helped show that B.1.1.7 (also called VUI-202012/01, for the first “variant under investigation” in December 2020), appears to be spreading faster than other variants in the United Kingdom. One of the polymerase chain reaction (PCR) tests used widely in the country, called TaqPath, normally detects pieces of three genes. But viruses with 69-70del lead to a negative signal for the gene encoding the spike gene; instead only two genes show up. That means PCR tests, which the United Kingdom conducts by the hundreds of thousands daily and which are far quicker and cheaper than sequencing the entire virus, can help keep track of B.1.1.7.
In other words, tests already being done in the UK can help identify whether a test result is consistent with being the new variant of COVID. I think this “fortunate coincidence” is actually the explanation for why the new variant became such a big story. You can see by watching this animation (press play) that different strains are always appearing and becoming more or less prevalent. This one happened to be easier to track, so certain decision makers (like NERVTAG, which includes no statisticians) saw this and conflated correlation with causation.
So if the new Covid-19 strain is more transmissible, why isn’t it taking over in every region?
Let’s look at these estimates of the percent of the UK population testing positive, broken down based on whether the test result “is consistent with” the new strain or otherwise. We can download data with estimates of COVID-19 infection rates from the Office of National Statistics. First let’s see the rates in two regions, the one where the new strain grew most rapidly and another region where it hasn’t.
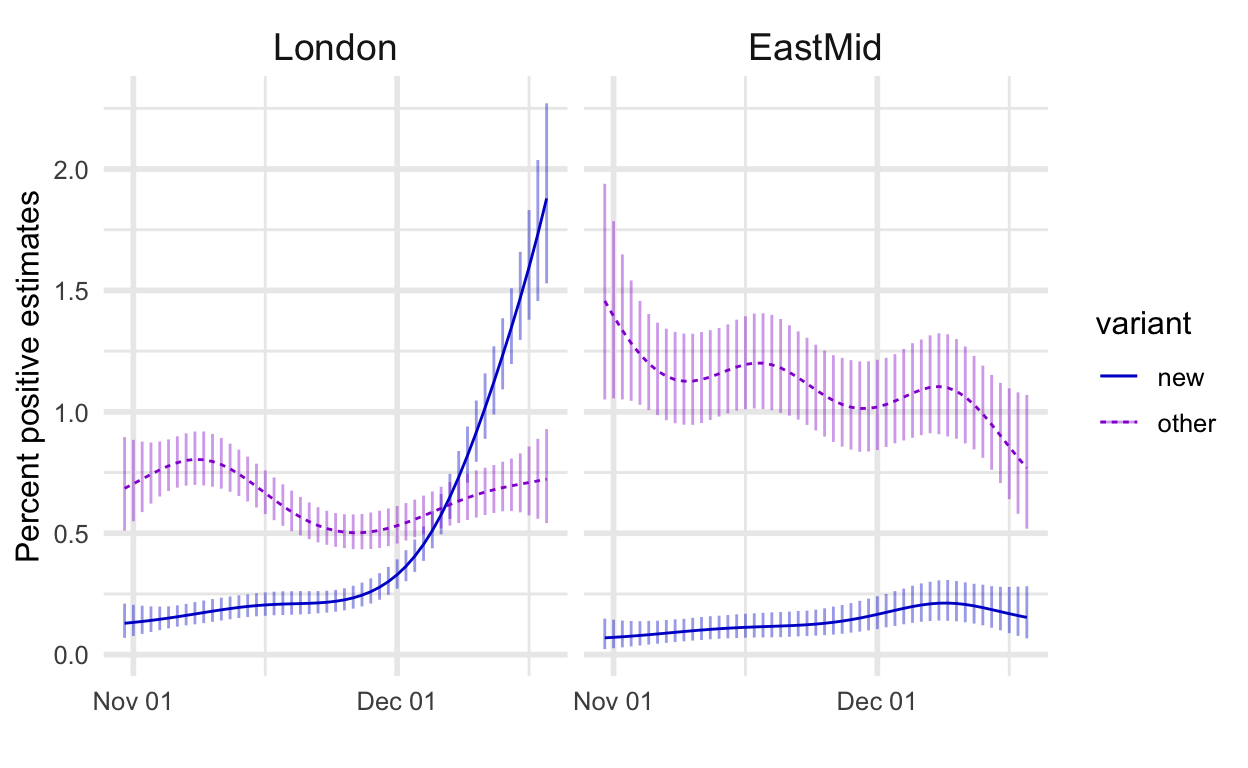
Next, here are all the regions sorted (top left to bottom right) in the order of the maximum estimated prevalence of the new strain.
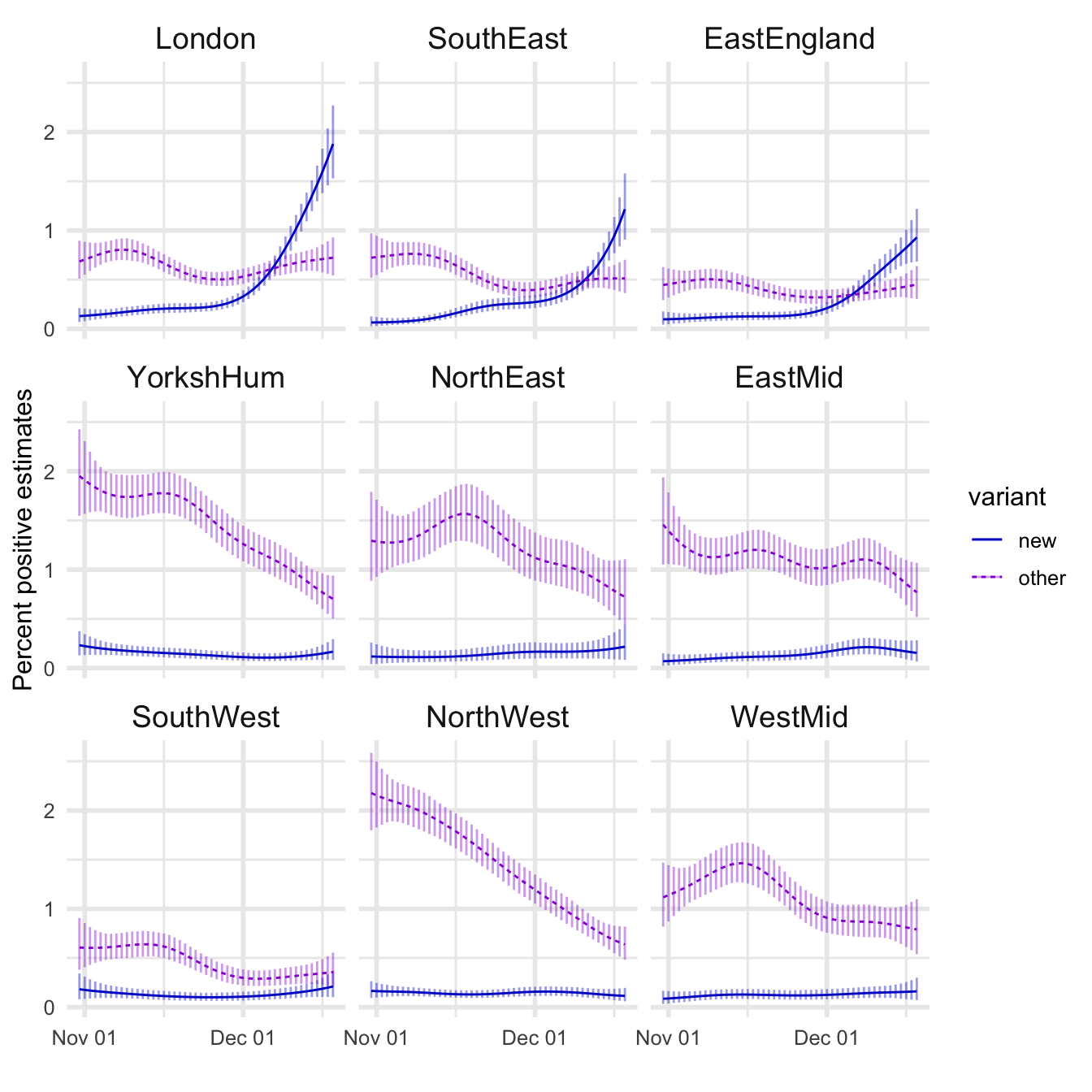
If the new strain has a biological advantage that makes it more transmissible why isn’t it taking over in every region? This is not a rhetorical question. One real possibility is that only some of the test results that are consistent with the new strain actually are the new strain, and other ones are similar but don’t have the same set of important mutations. If this were true then regions where the new strain hasn’t taken over could just be places where it has not yet reached, or reached recently enough that it’s still early, i.e. these regions are a month or so behind London in the trajectory for the new strain.
To repeat, None of this should be taken as scepticism about the importance of taking actions to control the spread of the pandemic. Whether this new strain is more transmissible or not, we already know there is continued widespread community transmission. We already know that millions more could suffer horribly, and die, and that emergency and healthcare systems and economies will be devastated if this virus is allowed to spread out of control. We already knew that more action was necessary to slow the spread before we learned of this new variant.
Still, the question of whether or not this new variant is more transmissible is important as a matter of scientific accuracy. And public trust.
So what else could explain the surge in London cases?
To be clear, I haven’t done the work of spelling out an alternate, behavioural explanation. Some have tried, but there just isn’t much good data available for that purpose. For example, mobility data apparently doesn’t show differences in activity levels between London and other parts of the UK throughout the relevant time period. Such data is incredibly coarse and not guaranteed to surface behavioral differences that could be important causal explanations.
Instead of thinking about what data is available and convenient to access (like the mobility indexes), ask yourself what kind of social information you would like to know if it were included as a question in the ONS COVID infection survey. Does the household have any contacts with schools? Where do household members work? Has anyone eaten indoors at a restaurant in the last week? Questions like these linked with actual test results – rather than aggregated by region in a mobility index – could be of tremendous help in tracking down how the virus is spreading and figuring out how to slow it down.
There’s almost no cost to simply asking a few more questions on a survey compared to the cost already going toward tests. It seems the only reasons this has not been done are a reluctance to know the answers to such questions (from e.g. desire to keep schools or restaurants open) and a reliance on big dumb data instead of intentional scientific thinking and deliberate study design.
The above is abridged from Professor Joshua Loftus’ original article: we added subheadings but cut detail about data sources. The original can be found on his website and is republished under Creative Content Attribution CC BY 4.0.



